Opened 11 years ago
Last modified 2 years ago
#2370 new defect
Improve performance of entity management for the AI
| Reported by: | Yves | Owned by: | |
|---|---|---|---|
| Priority: | Should Have | Milestone: | Backlog |
| Component: | AI | Keywords: | |
| Cc: | Patch: |
Description (last modified by )
Overview
Entities are created, destroyed and modified in the simulation code. The AI scripts also need access to these entities and they store a separate representation of the required entities. The AIProxy and AIInterface simulation components keep track of the differences that are interesting for AIs. These differences are passed to the AI for each AI update (doesn't happen every turn) and the sharedAI updates its internal (full) representation of entity data.
ApplyEntitiesDelta in shared.js does this updating. This does not only update the entities themselves but also entity collections. Collections can have filters associated and the collections are also updated according to these filters (entities are added or removed to collections).
Later each AI player works with entity collections by iterating through them and calling actions per entity or by adding additional collections or removing collections.
An important aspect of the current system is its support for multi-threading. Also check this forum thread for a detailed explanation of the interface and the multi-threading support.
The performance bottlenecks
From the current experience, the parts happening on the simulation side (AIInterface, AIProxy) are relatively inexpensive. ApplyEntitiesDelta takes way to long in late-game, which can be easily profiled because it's all in one function. I also think that iterating through collections adds way too much overhead and is another problem that can be less easily measured, because it's distributed across multiple AI objects working with entities and entity collections.
Approaches for improvement
Currently I see two approaches for improving performance:
1: Improve entitycollections in JS code
Using more suitable data structures for the collections could reduce the time for iterating and updating significantly. I've found an interesting overview of data structures that could help in this case. IIRC the AI often uses a kind of tree structure for some of its entity collections anyway (without using a tree for the data structure). Maybe it even makes sense to offer different types of collections that are optimized for different usages.
When optimizing Javascript code, the JIT compiler should also be considered. Using less polymorphic objects and avoiding deleting and adding properties allows the JIT compiler to optimize your code much better. I currently suspect that this polymorphic structure of entity collections is the main reason why the SpiderMonkey upgrade didn't improve performance for us.
There was some input from SpiderMonkey developers here. One suggestion was using Map instead of normal objects. I think Map isn't supported in SpiderMonkey 1.8.5, so you'd have to apply the patch in #1886 first or wait until the upgrade is completed.
2. Store entity data in C++, implement an interface to JS
C++ is generally faster and more predictable for optimization. C++ also avoids overhead for garbage collection and for passing structured clones to Javascript. On the other hand, there's additional overhead for each call from JS to C++. Arguments need to be converted to C++ types and the call itself causes overhead too. The SpiderMonkey developers even use a system called self hosting which implements parts of the JS engine in JS to avoid this kind of overhead! I don't know how many calls it needs until the overhead gets too big, but it's probably enough to cause serious problems. The fact that the context wrapping overhead for keeping the sharedAI in its own JS compartment was so big also tells me that the JS/C++ overhead could be significant in this case and needs special consideration.
Also keep in mind the requirements for multi-threading! We most likely still need a copy of entity data because the simulation code should be able to run independently from the AI code and because there are different requirements for the data structures.
Attachments (5)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (18)
comment:1 by , 11 years ago
| Description: | modified (diff) |
|---|
comment:2 by , 11 years ago
comment:3 by , 10 years ago
After having debugged through the code now for a few weeks, my suggestion would be to drop the entitycollections completely, for a few reasons:
- AI javascript code should mainly deal with ai topics. Currently it acts like a javascript database running triggers. And no matter how you try to optimize the code, I doubt you ever may speed it up enough to suit the games needs.
- Managing data by entitycollections creates many redundancies. Every change in simulation side component code must somehow be mirrored by entitycollections. May this be additional collections, filters or whatever.
- To a certain degree, optimizing entity collections depends on mozillas development of spidermonkey, jit and map implementations. As most of us already noticed, results are volatile and usually come with unwanted side effects such as the need for customisation of 0 A.D.s architecture.
Therefor I would recommend a step-by-step removal of entity collections and an introduction of a kind of ComponentRequestBroker.
Imagine the ComponentRequestBroker as AI-side counterpart of the simulation-side ComponentManager with the following features:
- QueryInterface(...) returns an IComponent* by returning a clone of IComponent* from ComponentManagers QueryInterface(...)
Cloning may occur only once a turn and only if the entity was updated between the current and the previous request for the entitys data.
- QueryInterfaceEIDs(...) returns a list of entity ids matching one or more filters.
- QueryInterfaces([eids]) returns an array of entities matching the specified array of ids.
This should
- remove the need to clone data which might never be used.
- ensure entity data is cloned only if the entity did change
- remove the need of data(base) management within the AI javascript code (imagine the data management overhead you would have, if you tried "on thread per (AI)player" using the current entity collections.)
- c/c++ maps can be used instead of looping javascript object properties or whatever.
- entity iterators might become fail-fast and therefor be cached during turns.
- simulation code and ai code are based on the same mechanics
- synchronizsation (future multithreading) of ai and simulation is reduced to a single point (if the ComponentRequestBroker requests a clone of a component from the ComponentManager).
- synchronizsation (future multithreading) the ComponentRequestBroker could develop "a feeling" for entities which are subject to the ai and might have been updated. Such entities could be cloned in advance by parallel worker threads.
- gain independency from mozillas spidermonkey development cycles
Just my 2 ct.
comment:5 by , 10 years ago
I'm working on that. I will post a github link as soon as there is enough to get a rough idea of it.
comment:6 by , 10 years ago
| Component: | Core engine → AI |
|---|
comment:7 by , 10 years ago
There should be at least a possibility for AIs not using ECs to avoid the costly update. An AI can route events directly to the relevant function/object by implementing an event dispatcher. If all AIs would use an event driven programming model ECs are not required at all and consequently API + AIs would be faster.
JavaScript is actually designed to support event driven applications with first class functions. Browsers provide an API to register an event handler (callback), so that mouse clicks or moves are handled by the callback only. The current programming model used in the O A.D. AI API is comparable to browsers collecting all events in a list and let e.g. a menu search within this list whether the user clicked an entry or not. If the user hasn't clicked that's a very costly NOP.
comment:8 by , 10 years ago
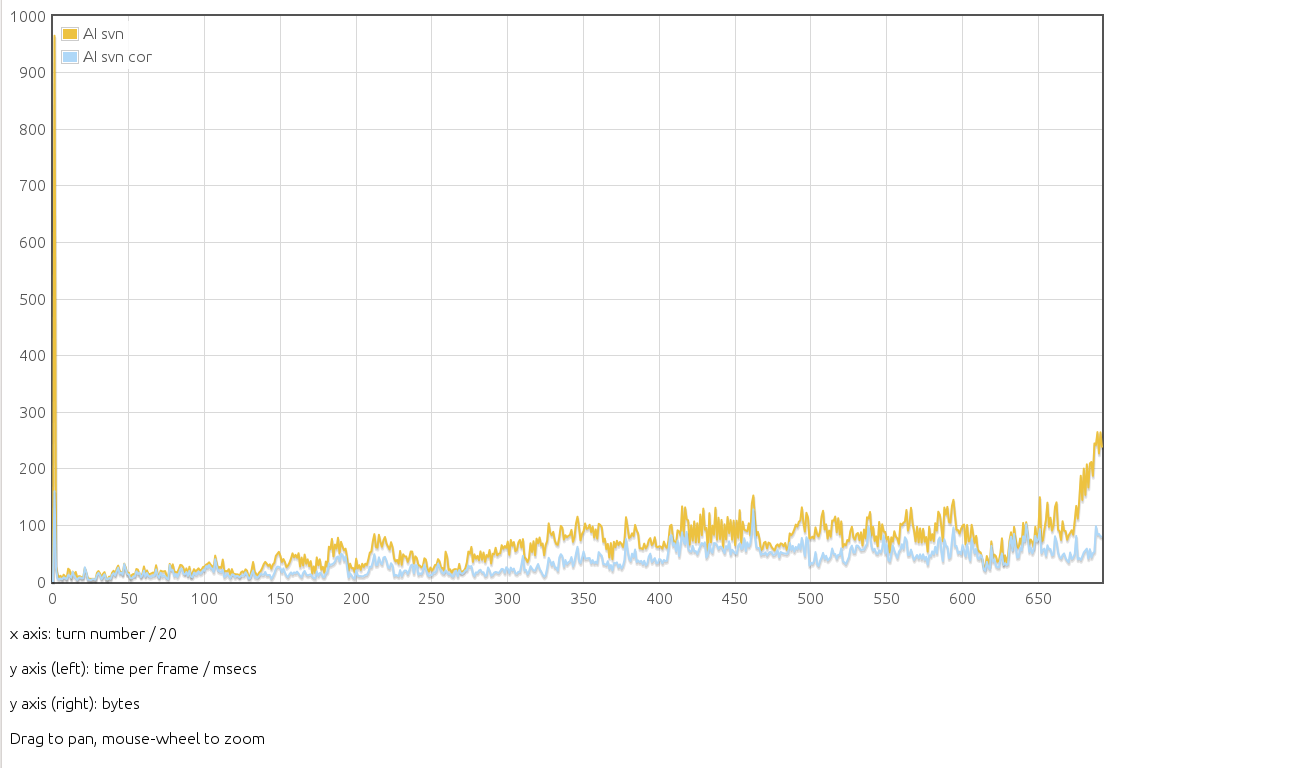
I've looked a bit at the entityCollection (EC) performances using a game with 4 petra AIs on the skirmishes/Thessalian Plains map by using a replay with 13000 turns and looking at the times as given in the profile.txt file. The timings I'm looking at include all the scripted ai time (shared ai included) but not the commands sent to the Engine. I've used Yves scripts to display them.
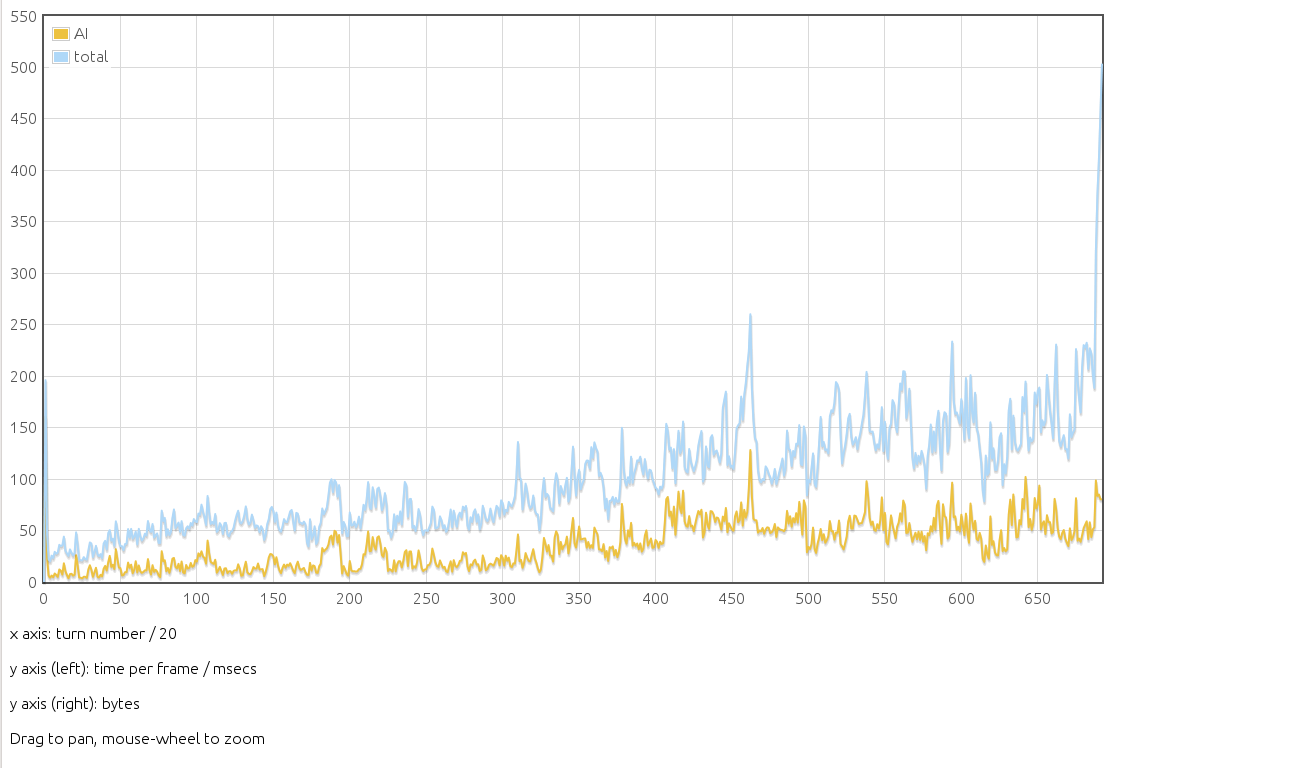
The present svn state is shown in AI-svn-cor.png by the yellow curve (the Y axis is labeled time per frame, but I guess it is time per turn for replays ?). There were two obvious features: huge initialization time and huge increase in late game. The first feature was a bug (which was apparent only on very few maps) and the second was a pretty inefficient use of one EC. After fixing both problems, we get the blue curve, which shows nearly a factor 2 gain in that game with 4 AIs (increasing with the number of entities). To have a feeling of the proportion of time spent by the AI scripts, AI-total.png shows the AI time (after previous correction) compared to the total time of the replay.
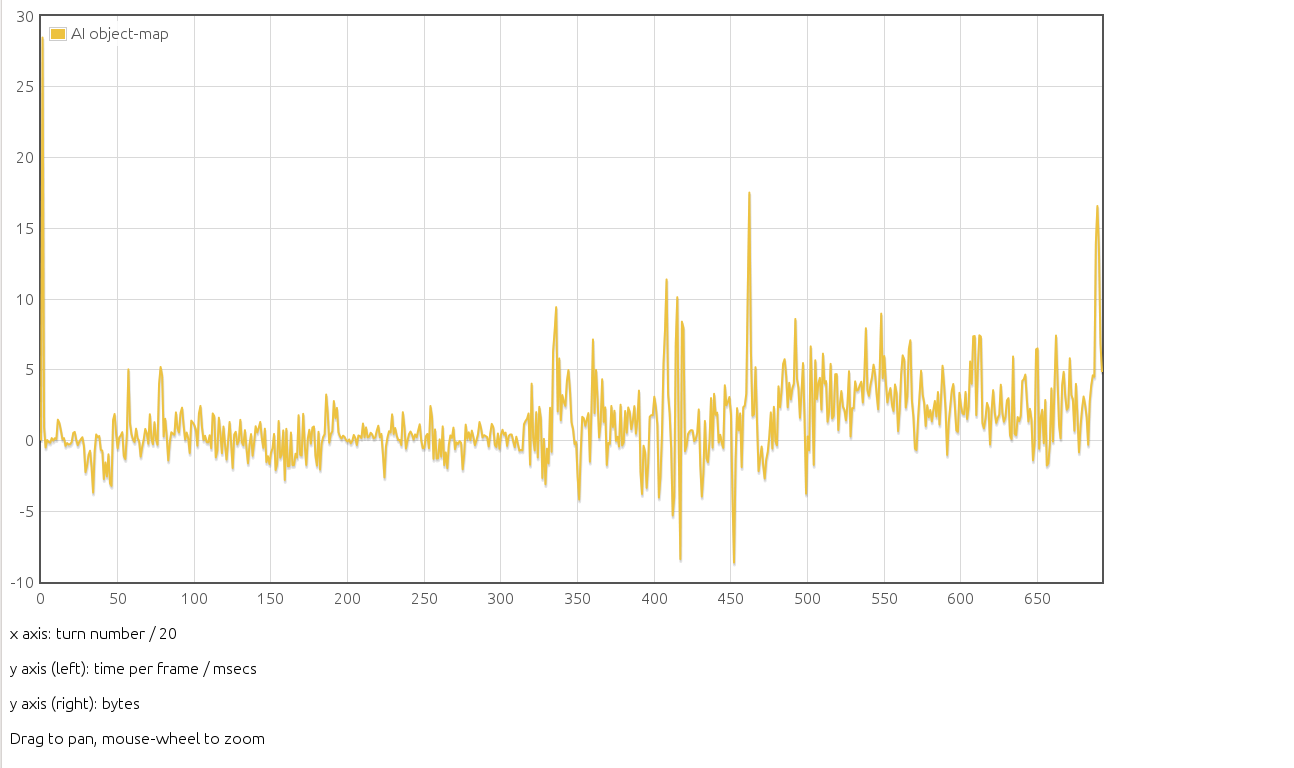
Finally, all that profiling was in fact done in order to check the effect of replacing EC-objects by EC-maps. There are in fact no big differences, so we'd better look at the difference between the two timings. This is shown in AI-object-map.png which shows the time with objects minus the time with maps. There is a small effect with objects slighly slower than maps in late game (by about 2 ms for an average 50 ms). This could still be within the uncertainties, but as the code with maps is also cleaner, I propose to switch to maps for ECs.
by , 10 years ago
| Attachment: | AI-svn-cor.png added |
|---|
by , 10 years ago
| Attachment: | AI-total.png added |
|---|
by , 10 years ago
| Attachment: | AI-object-map.png added |
|---|
comment:12 by , 10 years ago
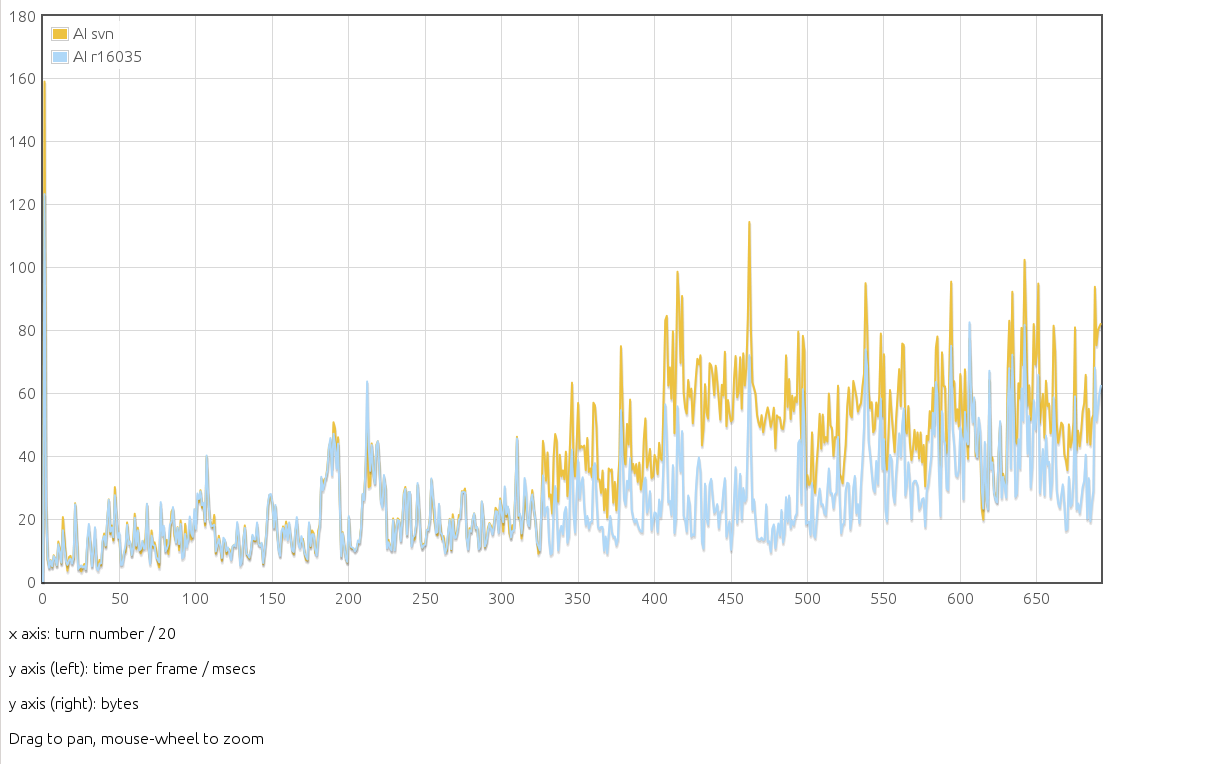
16035 contains further improvment on the ai. The main effect being that one function (for new trade route prospection) is quite slow and was called too often. Profiling on the same 4-AI game as the previous plots, we get the new plot AI-r16035.png where the yellow curve noted svn correspond to r16027 and the blue curve to the new r16035.
by , 10 years ago
| Attachment: | AI-r16035.png added |
|---|
AIs do everything with entity collections.
I've got a few very much not rigorous numbers to get an idea of what we're dealing with here. They're taken from EntityCollection.js so they're more than likely under the real numbers (particularly the number of direct access, since that's not done only with those Entity Collections).
Over the fist 15 minutes of a game with 1 AI doing its stuffs:
Iterations over whole EC: ~48000
Actual Iterations: 1,314,517
Calls to "Filter": 10843
Direct accesses: 888,215
Additions: 1721
Deletions: 1193
And on average it seems like there were (every 5 AI turns):
550-800 new complete iterations
150-200 new Filtering calls
20,000 direct accesses
0-15 deletions
10-20 additions
So that gives an overview of what we have to deal with: a ton of iterations (like really, really, really a lot.) A ton of direct access. Comparatively rare additions and deletions.
I'll try to get some more precise information.