Opened 9 years ago
Last modified 5 years ago
#3588 new defect
General pathfinder optimizations
| Reported by: | wraitii | Owned by: | |
|---|---|---|---|
| Priority: | Should Have | Milestone: | Backlog |
| Component: | Simulation | Keywords: | pathfinding |
| Cc: | Itms | Patch: |
Description
For the short-range pathfinder, see #1942.
This ticket deals with various ways to optimize unit motion further. There are a few components at play here:
- CmpUnitMotion, which decides how units move, and makes the move.
- Long-range pathfinder, which uses the hierarchical pathfinder and JPS
- Short-range (vertex) pathfinder, to compute shorter distances that take units into account
- ObstructionManager, which keeps track of all obstructions in the game (buildings, tree, units, etc.)
Some profiling on A19 games (circa [17120]), on real MP 3V3/4V4 games have shown me the following.
On the C++ side, a turn is basically UpdateComponents, which is:
- 30% "FinishAsyncRequests"
- 30% "ProcessSameTurnMoves"
- 30% "Broadcas Message" (itself mostly unitmotion and rangemanager)
- 10% Pathfinder::updategrid
So it's basically 70% pathfinder, 10% unitMotion (mostly sending messages), and the rest is the range manager running queries.
There are a few more interesting details:
- UpdateGrid is 50% HierarchicalPathf update, which is slow as it uses std::maps, mostly.
- 20% rasterization in the obstructionManager
- The pathfinder itself is about 50% short-range pathfinder, 20% long.
- of the Long-range pathfinder, it's 15% (!!!) MakeGoalReachable in the hierarchical one, the JPS is basically only 3 to 4%
- short-range is a bloody mess, it's all in small bits in ComputeShortPath, see #1942
So what we can tell here is that the hierarchical pathfinder is slow. It should probably be moved to use another container than map, and we need to make MakeGoalReachable MUCH faster.
MakeGoalReachable tries to find the accessible goal navcell that's closest to us. This ends up basically being a pathfinding problem, and I think we should run a raw form of A* in some situations, as it would be much faster than iterating over all cells (96*96) which is what we currently do in most cases. This is basically the function "RegionNearestNavcellInGoal", which should be optimized. Also needing optimization: PathGoal::NavcellContainsGoal.
Also, we do not necessarily need exactly the closest cell accessible to us, so we should run with some approximations here.We might even get away with letting UnitMotion handle the very end of the path.
For information, UnitMotion is 30% CheckMovement and 25% MoveAndTurnTo, because the former uses "TestLine" and the latter broadcasts a message toalmost all entities on Earth. The use of "GetUnitsOnObstruction" is also bad, and should be remedied somewhat.
Attachments (13)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Change History (44)
comment:1 by , 9 years ago
by , 9 years ago
| Attachment: | optimize-rasterize.patch added |
|---|
comment:2 by , 9 years ago
I had a look at the RasterizeRectWithClearance function that used quite some time in your profiles, see http://irclogs.wildfiregames.com/2015-11-08-QuakeNet-%230ad-dev.log Here is a patch which should decrease its time by a factor 2 or more (I've checked that it gives exactly the same Hash code, but didn't profile it). Could go to a19 when confirmed.
by , 9 years ago
| Attachment: | short-rangememusage.patch added |
|---|
comment:4 by , 9 years ago
Good, thanks for your work!
Attache patch, short-rangememusage.patch, is an aggressive optimization of the short-range pathfinder's memory footprint (see #1942). I haven't reprofiled the memory usage but it should be way down.
This both optimizes the pathfinder itself (by around 5/10%, it seems) and the game, as it reduces fragmentation (and the short-range pathfinder was basically responsible for 50% of the C++'s allocations). Over the course of a complete game I think it could speed the pathfinder up by around 10%.
The price to pay is an increased ugliness to the code itself, because I haven't tried using memory pools yet. A proper fix would use those, but I wanted proof of concept.
I'm running some numbers to see if it would still be interesting for A19 or not.
comment:5 by , 9 years ago
I ran a comparison with vanilla SVN: the game does seem to run substantially smoother. I ran 2 instances with the optimization, one without, an the total time to process 3000 turns of an MP 3V3 nomad game were:
-Opt run 1: 192000 ms with 24% in the short-range pathfinder
-SVN run 1: 235000 ms with 27% in the short-range pathfinder
-Opt run 2: 217000 ms with 24% in the short-range pathfinder
Given that the other components, in proportion, took more time, I think it's safe to say this optimization speeds the game up by about 3 to 4%, and possibly more (up to about 10%).
by , 9 years ago
| Attachment: | profileReference.png added |
|---|
profiling on a non-visual replay 2vs2 with 4 Ais
comment:6 by , 9 years ago
Looking at the profile given here, the function PointIsInSquare is a good candidate to be inlined. Here is a patch doing that. The gain seems to be about 0.4% on nonvisual replays.
by , 9 years ago
| Attachment: | profileR17297.png added |
|---|
comment:9 by , 9 years ago
The Hierarchical pathfinder was optimized in r17284, resulting in the new profile (profileR17297.png) attached. Comparing both, we see that the huge number (63 millions) of calls to NavcellContainsGoal is now gone, and consequently, the regionNearestNavcellInGoal which represented 6.4% of the replay time is now reduced to 1.1% From this profile, we also see that the updateGrids (both for the Hierarchical and long pathfinder) account each for 15% of the replay time.
by , 9 years ago
| Attachment: | profileR17310.png added |
|---|
comment:11 by , 9 years ago
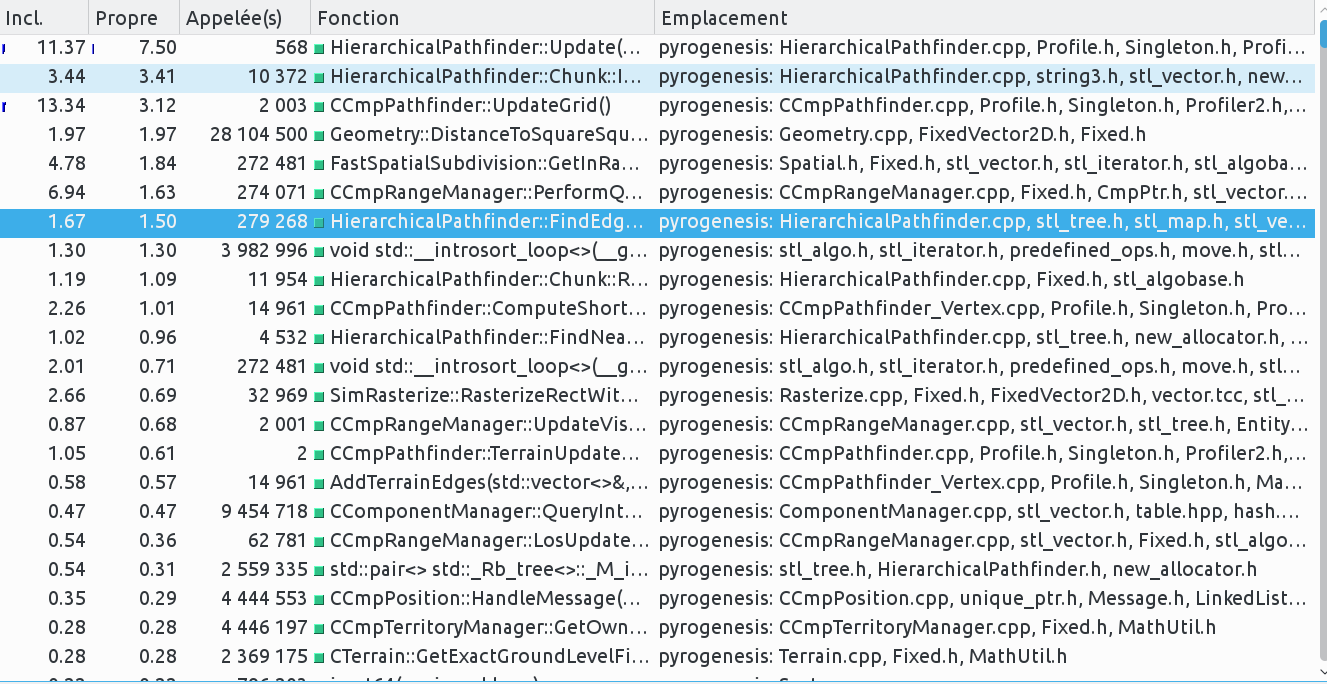
As can be seen comparing the profiles from r17297 and r17310, the HierarchicalPathfinder function FindEdges drops from 5.6% of replay time to 1.7%, most of the time being due to a large amount of insert trials (34 millions from the r17297 profile, now decreased to 2.6 millions).
comment:14 by , 9 years ago
In the previous profile, we see that the function DistanceToSquareSquared takes about 2% of the replay time. r17350 simplifies the code (taking advantage of the symmetries of the problem) and makes it faster, decreasing it to 1.3%.
comment:16 by , 9 years ago
As seen from the previous cachegrind profile, the grid update of the hierarchical pathfinder takes a large part of the non-visual replay: in r17412, it represents 11% with 7% internal to the Update function. The patch in r17413 changes the way the loops are done, reducing this to 7% for the grid update with 3% internal to the Update function.
comment:17 by , 8 years ago
| Milestone: | Alpha 20 → Alpha 21 |
|---|
This is still a work under progress so I don't backlog it, but pushing it so it doesn't delay the release.
by , 8 years ago
| Attachment: | InitRegions.patch added |
|---|
follow-up: 19 comment:18 by , 8 years ago
| Keywords: | review added |
|---|
Some micro-optimizations in HierarchicalPathfinder::Chunk::InitRegions:
- The check for infinite loops is not needed since RootID(n,...) terminates after < n+1 steps (x gets strictly smaller with each step).
- We can avoid some RootID calls by checking if we just connected the same IDs, i.e. if the previous DownID and the previous LeftID were non-zero.
- Computing the RootIDs can be simplified: If we computed RootID(1, ...), ..., RootID(n, ...), the value of RootID(n+1, ...) is simply either n+1 (if it's a fixed point) or the RootID of whichever ID it gets mapped to (which we already computed).
comment:19 by , 8 years ago
Replying to fsincos:
Some micro-optimizations in HierarchicalPathfinder::Chunk::InitRegions:
I would suggest to open a new ticket for this, to avoid forgetting it in this one, already too long. If it's worth, you may want to add a graph showing performance improvement, as described here.
comment:20 by , 8 years ago
That's ok if you want to keep it here, I won't forget it. Else if you create a new ticket please put me in Copy. :)
comment:21 by , 8 years ago
Hi, I took a look at the patch and it looks nice :)
I have one comment and one question:
- I am going to remove your last change, because it's not trivial to prove this induction, so the code is less clear, and in any case you don't save anything (your proof is right, so
connect[connect[i]];is either equivalent either worse than callingRootID). - Would you like to have your name in the credits? If yes, do you want both your nickname and real name or only one in them?
Also I read in the IRC logs that you were working on the vertex pathfinder the last time you were active. If you don't succeed at something, the vertex pathfinder will probably be replaced so it's not too much a problem if you can't manage to improve it :)
Thanks for your work!
by , 8 years ago
| Attachment: | Cleanup1.patch added |
|---|
comment:22 by , 8 years ago
- That last change (connect[connect[i]] instead of RootID) is indeed unneeded.
- If I contribute something significant, I'll think about putting my name on the credits. However, at the moment I'm just doing some small stuff for fun.
To say I've worked on the short-range pathfinder would be an overstatement, but I've put together a couple of small patches. This one is the first of them (took me about 20 minutes, so it's not like it's much). The memory fragmentation gets reduced a bit and the code is a bit cleaner. Barring oversights, it should produce exactly the same results; if that isn't needed the number of terrain edges can be reduced by only ending edges if that side is passable (this combines some edges). The longer edges resulting from this would also be more likely to block rays.
As a bonus, the CheckVisibility functions have been updated to eliminate shifts and overflows from the dot products. The CompareLength functions could receive the same treatment (x*x + y*y > u*u + v*v <=> x*x - u*u > v*v - y*y).
comment:24 by , 8 years ago
Here is a small cleanup / optimization of the TestRaySquare functions and the SquareSAT function in source/simulation2/helpers/Geometry.cpp. The trick (all of k +- l +- m have the same sign) <=> |k| > |l| + |m| allows us to reduce the amount of multiplications done.
This trick could enable checking visibility against squares directly (as opposed to checking each edge) which would remove one of the bigger memory problems (no more splitting required). It might also be faster from a pure calculation standpoint, but I don't know enough about the frequencies of the code paths to state this with any certainty.
by , 8 years ago
| Attachment: | geometry2.patch added |
|---|
Rough first version of the mentioned CheckVisibility trick.
comment:25 by , 8 years ago
| Keywords: | review removed |
|---|
I really like both of the patches!
I have a general comment about the changes: it would be nice to better document them and add as much geometrical explanations as possible.
For instance, could you rename CrossGTZero to something that would be more meaningful? The comment already explains what it computes but it could use a description in terms of geometry. I can't figure out what it does, given two vectors on a piece of paper
Another example: you changed the TestRaySquare documentation: now it's impossible to determine where the separating axis theorem is used because it's hidden in the optimized computations. You should add details.
As a rule of thumb, each time you delete a comment, or when you add a non-trivial optimization, please write some documentation :)
Keep up the good work!
by , 8 years ago
| Attachment: | geometry1.patch added |
|---|
Small geometry cleanup to enable further optimizations.
by , 8 years ago
| Attachment: | geometry1.2.patch added |
|---|
Initial implementation of replacing CheckVisibility with a TestRaySquare-based version.
by , 8 years ago
| Attachment: | UnorderedSetHierPath.patch added |
|---|
comment:27 by , 8 years ago
Attached patch uses a hash table to store reachable regions, which from testing should be around 2 to 3 times as fast. I had a checksum change but I need to check with a clean SVN.
comment:28 by , 8 years ago
| Keywords: | patch rfc added |
|---|---|
| Milestone: | Alpha 21 → Alpha 22 |
Grmbl, keywords everyone!
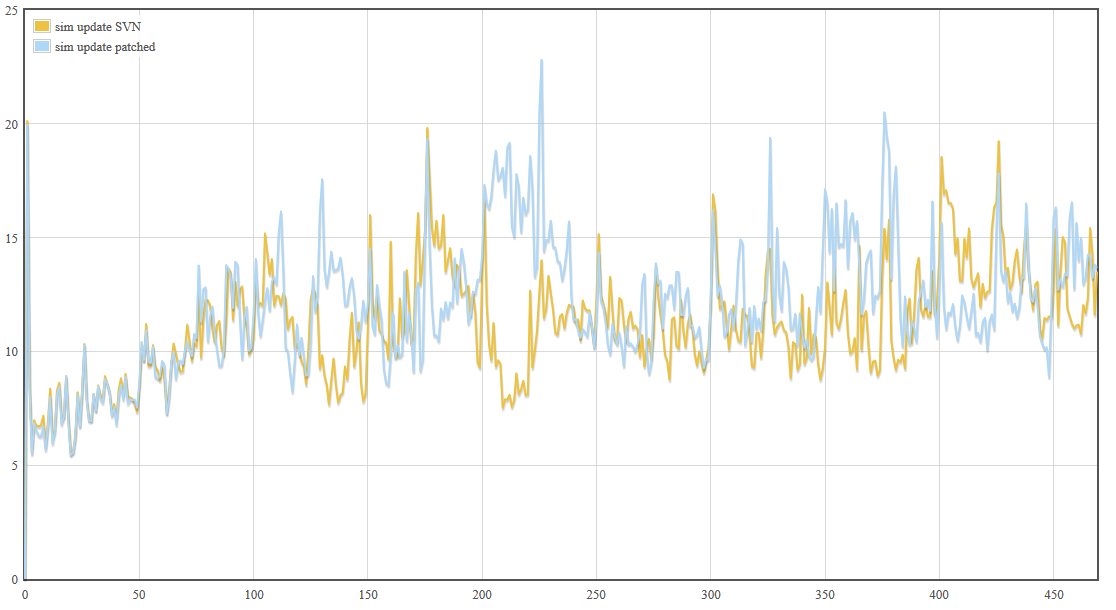
The latest patch from wraitii does change the simulation state, and it does not improve at all the performance as far as I could see (see attached profiling graph, for a large game). So IMO it should be forgotten.
I will review fsincos patches after the release of A21.
by , 8 years ago
| Attachment: | profile_unordered.png added |
|---|
comment:30 by , 8 years ago
| Keywords: | patch rfc removed |
|---|---|
| Milestone: | Work In Progress → Backlog |
comment:31 by , 5 years ago
| Component: | UI & Simulation → Simulation |
|---|
Move tickets to Simulation as UI & Simulation got some sub components.
Some comments about memory.
Those numbers are mostly indicative, they are not over the course of a whole game (mostly the middle of a MP 3V3), since I was too lazy to wait for the end of the replay:
Looking at transient/temporary memory: